

| AfC | fernand0: Andrew Cowie here. Lag check: this message sent at 20:55:00 UTC |
|---|---|
| fernand0 | ok |
| trulux | ese fernand0! |
| fernand0 | my clock says not much lag |
| trulux | ;) |
| AfC | Just wanted to know whether I should try connecting to a different server. If this is fine, it is fine :) |
| fernand0 | it's fine |
| AfC | fernand0: you may want to add this link to the topic: |
| AfC | fernand0: http://www.operationaldynamics.com/reference/talks/TrendsUnixInfrastructure/ |
| AfC | Those are some slides to accompany my chat. |
| fernand0 | ok |
| fernand0 | too long |
| fernand0 | he |
| AfC | ok |
| fernand0 | :) |
| AfC | [ready, start logging whenever] |
| fernand0 | so far so good |
| fernand0 | Hello, |
| fernand0 | we have here today Andrew Frederick Cowie, from Australia. His company is |
| fernand0 | Operational Dynamics. |
| fernand0 | |
| fernand0 | He will talk about " Modern trends in Unix infrastructure |
| fernand0 | management [systems administration." |
| fernand0 | |
| fernand0 | We are grateful for this talk. |
| fernand0 | We are also grateful for you all comming |
| fernand0 | here. |
| fernand0 | |
| fernand0 | There is some material for the presentation at: |
| fernand0 | http://www.operationaldynamics.com/reference/talks/TrendsUnixInfrastructure/ |
| fernand0 | |
| fernand0 | As usual, this channel is for the talk, #qc for questions and comments, and |
| fernand0 | #redes for translation. |
| fernand0 | |
| fernand0 | AfC ... |
| AfC | Good evening. Of course, it's morning here, GMT+11 |
| AfC | Os pido disculpas por que desafortunadamente no hablo español, aunque soy |
| AfC | consciente de que muchos aqui si que lo hablan como lengua madre. |
| AfC | Yo crecí |
| AfC | en Canadá y tambien hablo francés, pero dudo que esto me ayude mucho hoy. |
| AfC | Como consecuencia, voy a hacer mi presentación en Inglés, pero intentaré no |
| AfC | usar palabras muy coloquiales o frases idiomáticas. |
| AfC | [a friend translated that for me :)] |
| AfC | So what I want to talk to you about today is |
| AfC | about some trends that I have observed |
| AfC | in the Infrastructure Management world. |
| AfC | It's definitely a Unix / Linux centric chat, |
| AfC | although I should observe that the problem of managing Unix systems |
| AfC | is inevitably a problem of managing systems from different "vendors" - |
| AfC | ie, a heterogeneous network. |
| AfC | That said, I pity the people with Windows servers in their datacenters. |
| AfC | [[[go to slide 1 http://www.operationaldynamics.com/reference/talks/TendsUnixrInfrastructure/img1.html ]]] |
| AfC | So as I hope most of you have seen, I wrote up a few slides for today. |
| AfC | They are "informal" in the sense that this isn't a long winded carefully crafted set of corporate slides. |
| AfC | [I do that for physical conferences] |
| AfC | but I wanted to provide some "eye candy" for you to as I talk |
| AfC | This talk is about TRENDS which usually is defined to mean "the way things are expected to be in the future" |
| AfC | but before I can get to far with that, I need to sketch out some history |
| AfC | specifically, Unix and Linux history According To Andrew (tm) |
| AfC | The funny thing about the last 30 years has been the cyclic moves between centralized and decentralized systems |
| AfC | early on we had one big Unix machine, with lots of "dumb" terminals connected to it by serial cables. |
| AfC | Mulitple users, on a single multiprocessing machine. That was the way mainframes were, and when Unix came on the scene, it was awesome at this. |
| AfC | This started to change with the advent of the graphical workstation for scientific modeling, visualization, and graphics. The workstations from SGI, Sun, HP, Digital, etc were very powerful machines in their own right, but they had an entire Unix installation on each one. |
| AfC | Imagine! Instead of one Unix machine in a department, there were now 10 - the central one, and then all these crazy workstations. Suddenly, the challenge of managing Unix exploded in complexity. |
| AfC | Things like files and administration were, in those early days, still centralized. This is when NFS and NIS came out of Sun. |
| AfC | A short while later... |
| AfC | [Notice the suspicious lack of dates :)] |
| AfC | IBM launched the Personal Computer. With the meteoric rise in popularity and affordability of the desktop PC, suddenly there was impressive computing power on individual machines ... but they were all disconnected, standalone, (and, not Unix). |
| AfC | Data transfer was "how fast can I carry a floppy disk from one person to another". |
| AfC | Then came the PC networks - file services like Banyan, Novell Netware got their start in these environments. And her we had VERY slow networks trying to ship files around from a central file server. |
| AfC | About this time came the small Unix variants - Xenix, later SCO Unix; Minix; the *BSDs; and then one day, Linux. |
| AfC | And the rest, as they say, was history. |
| AfC | Now. This is nothing terribly novel or new. But consider these trends as they have impacted the datacenter. |
| AfC | Today, one of the major challenges is enterprise computing - providing the computing power necessary for some business application. Perhaps that is an e-commerce platform like E-Bay, or the financial back end of a bank. |
| AfC | Two consistent themes that emerge are attempts to SCALE these platforms. |
| AfC | to deal with increased load. There are two strategies, of course - you can scale vertically; that is, |
| AfC | add more CPUs, faster drives, more memory, faster network switches; or you can try and scale horizontally, |
| AfC | that is, spread the load around smaller but more numerous machines. |
| AfC | In a typical e-commerce platform, you end up with both |
| AfC | ie, lots and lots of web servers (small machines), a smaller number of application servers in the middle layer (on stronger mid range hardware) all standing on a central core database engine running on some massive huge machine with as many CPUs and as much memory as can be afforded, and with a massive disk array behind it. |
| AfC | That's the standard "three tier architecture" (we'll be returning to that in a bit) |
| AfC | but basically it means large numbers of machines - *many of which are different*. |
| AfC | So as people try to scale further and further horizontally, they end up running out of rack space in their datacenter to put all these servers. |
| AfC | which is pretty much where the market pressure that led to "blade servers" came from - smaller and smaller servers packed into as small a space as possible. |
| AfC | Never mind how much power they draw or how much heat they generate... |
| AfC | So not too long ago we had 10s of machines to manage... now we typically have 100s or more to manage in the same space. |
| AfC | Clearly, you can't systems administer those by hand. |
| AfC | (which is another theme we'll return to) |
| AfC | Of course, as large shops started to have thousands of machines, they started looking for ways to *cut down* the number of physical servers ... which led to the trend towards "virtualization", which is running multiple virtual servers on a single physical machine. |
| AfC | One of my colleagues, Director of Operations at Charles Schwab (an online trading brokerage), noted that they're trying to cut from > 4000 machines down to 1500. |
| AfC | (Yikes!) |
| AfC | Virtualization is no magic silver bullet, however much the people selling virtual server solutions might like it to be: |
| AfC | To quote Robert Heinlein - "There's No Such Thing As A Free Lunch" - if your application is CPU bound, then piling more server instances on a physical machine doesn't get you anything - they're all fighting for the same CPU resource. If they're IO bound, and IO is highly available relative to CPU, then perhaps you've an opportunity to get advantage |
| AfC | however, (and this is the point that everyone misses) 50 virtual web servers on a single physical machine *all have to share the same NIC*!!! |
| AfC | and suddenly, the I/O slack (disks) that you thought you were getting advantage from is negated by the I/O through the network interface being jammed up. |
| AfC | So the summary there is that there *are* no easy answers, and neither blade servers (increased physical density) or virtual servers (increased logical density) are an automatic solution to your challenges. |
| AfC | That was all quite generic, I grant you. It bears on the subject "Unix Infrastructure Management" quite directly, though .... all these thousands of machines are running Unix (or more likely Linux) ... and YOU are the admin who has to make it work |
| AfC | - |
| AfC | Another trend (and this will be quick) that we've seen evidence of is the proliferation (massive growth) of web interfaces to systems. |
| AfC | Any of you who have broadband at home no doubt have a little hardware modem/firewall/router/switch device... and you configure it with a web interface, right? |
| AfC | Well, everything else is like that to, these days. |
| AfC | The load balancers are controlled by a web interface... |
| AfC | The firewall config is controlled by a web interface... |
| AfC | The packet shaper is controlled by a web interface... |
| AfC | The database traffic monitor is a web interface... |
| AfC | Your trouble ticket sytem is a web interface... |
| AfC | Your knowledge base is a web interface... |
| AfC | You get the idea. |
| AfC | The last one is fair. But there are a few more which are of great concern: |
| AfC | Your system monitoring & alert system is a web interface. |
| AfC | YOUR DAMN WEB SITE IS A WEB INTERFACE :) |
| AfC | The trouble for Unix admins is that we quietly, and without anyone stopping to think about it too much, went from a world where we could certainly control a single system node from a command line interface, |
| AfC | and with careful effort (see later in the presentation) could drive an entire production platform of 10s or 1000s of machines using command line tools, |
| AfC | to a situation where you have to log into endless *specific* web interfaces to adjust the configuration of devices and sub-systems. |
| AfC | YADWIIHYLIT |
| AfC | Yet |
| AfC | Another |
| AfC | Damn |
| AfC | Web |
| AfC | Interface |
| AfC | I |
| AfC | Have |
| AfC | To |
| AfC | Log |
| AfC | In |
| AfC | To! |
| AfC | YADWIIHTLIT |
| AfC | (whatever) |
| AfC | :) |
| AfC | the point is that the one thing that can protect your sanity - automating systems administration tasks, has been serious undermined by the fact that you can no longer centrally define, manage, or repair a datacenter in its entirety. |
| AfC | [And worst of all, how many different logins and passwords for each stupid device and sub-system do you have to remember / record somewhere? Out of control. And no, SNMP doesn't cut it] |
| AfC | [[[ Time for the next slide. See http://www.operationaldynamics.com/reference/talks/TrendsUnixInfrastructure/img2.html ]]] |
| AfC | I'm not going to belabour the point about complexity being your enemy. But I will comment on one trend which is of great concern: because they are independent commercial entities, vendors do not work together to provide you with an integrated solution to your problems. |
| AfC | This isn't about whether or not you outsource to IBM; this is about the simple fact YOU are the ones who have to deal with the complexity of your system |
| AfC | and very simply, the more interconnections you have, the worse off you are going to be. |
| AfC | I'm going to jump to another set of slides for a minute. |
| AfC | Because I want to show you something: |
| AfC | Please load up: |
| AfC | http://www.operationaldynamics.com/reference/talks/SurvivingChange/img16.html |
| AfC | [I'm watching the web log, so I know who is paying attention :)] |
| AfC | [Come on, yes, this means you. Load that link :)] |
| AfC | Now follow the slides until you get to img24, that is |
| AfC | http://www.operationaldynamics.com/reference/talks/SurvivingChange/img24.html |
| AfC | Those pictures are a simple visual depiction of the effect of change. You add one more node to a system, and the resultant change you have to deal with IS NOT LINEAR. |
| AfC | The problem is that the resources you have to deal with are even in the best case scenario, ONLY linearly growing... which means |
| AfC | that there is always a gap between available resources and the complexity of the system you have to manage. |
| AfC | So if you want to be a happy Unix person, you need to approach things in new ways. |
| AfC | Back to today's slides: |
| AfC | http://www.operationaldynamics.com/reference/talks/TrendsUnixInfrastructure/img2.html |
| AfC | the sort of complexity evident in this diagram is common in Unix / Linux production platforms, and yet managing change to that platform is hellishly difficult - with the result that mistakes are made, which result in down time, increased costs, lost revenue, etc. |
| AfC | And yet, the vendors of individual products are all happily adding features which supposedly help you, but end up simply sending you further down the direction of having an overly complex, unmanageable, unmaintainable system. |
| AfC | So, before I go on, |
| AfC | Creo que voy a tomar una pequeña pausa aquí para que los que están |
| AfC | traduciendo tengan una oportunidad de llegar hasta este punto. |
| AfC | Espero que |
| AfC | todos me estén siguiendo sin problemas. |
| AfC | |
| AfC | |
| AfC | [[[ next slide: http://www.operationaldynamics.com/reference/talks/TrendsUnixInfrastructure/img2.html ]]] |
| AfC | oops,cut and paste error. Slide 3 |
| AfC | [[[ http://www.operationaldynamics.com/reference/talks/TrendsUnixInfrastructure/img3.html ]]] |
| AfC | *there* :) |
| AfC | [I told you these slides were mostly eye - candy, but hey, it's all fun] |
| AfC | So I want to talk now about a strange trend that I've observed in industry over the last few years: mass simplification |
| AfC | I've been talking about the "typical" e-commerce platform. 3-tier architecture of web servers, application servers, and database engine |
| AfC | which is what is underneath any big .com site (eBay, amazon.com, etc) and likewise underneath any big enterprise system (like the financial system in a large company, a bank's web site, etc). |
| AfC | There is no problem with this. It works fine. It is a relatively well understood environment |
| AfC | but it is bloody COMPLEX |
| AfC | and bloody EXPENSIVE |
| AfC | So I want to mention 3 examples of people doing things a little differently. |
| AfC | as an illustration of thinking in creative ways about how to manage complexity, and how to manage change |
| AfC | [the trend is that people ARE thinking creatively. Wow!] |
| AfC | At Yahoo!, |
| AfC | they have three tiers, |
| AfC | but it's all ... shifted ... up one layer. |
| AfC | When you hit yahoo, you actually hit a squid reverse-proxy web cache |
| AfC | they have a huge farm of them. |
| AfC | all their content is properly fine tuned with appropriate expires, last-modified, cache settings |
| AfC | so most of their content quickly gets up to the squid caches and is served from there. No need to hit the "real" web server.... |
| AfC | (which means that the squid boxes are, in effect, acting as the web servers) |
| AfC | Further, even for thier most volitile content, their squid boxes are configured not to bother going back to the web servers for 5 seconds. |
| AfC | which further reduces their load. |
| AfC | The next strange thing they did is that the web servers ARE the application servers. The web servers run PHP, and that's where their application layer is. They don't bother (at least in many of their applications) having a middle tier of app servers, which means they don't have to deal with the network complexity of trying to load |
| AfC | balance and manage connections between web servers and app servers |
| AfC | (smart move - wiped out an entire layer of complexity... and one which is notoriously hard to analyze and debug) |
| AfC | finally, they use MySQL in replication mode - 10s of database servers that are all just read only slaves; there's one write master server somewhere, but MySQL can and does handle all that transparently without too much trouble |
| AfC | So how's that compared to a Websphere + DB2 + huge massive IBM server, or Weblogic + Oracle + huge Sun server? |
| AfC | it's low tech, but it has less complexity; is easier to manage and tune; and we all know Yahoo has high performance. |
| AfC | So that's an example of doing something architecturally that can radically change the Unix admin challenge; but here's one better. Google. |
| AfC | Now, admittedly, they have more servers than there are people in China |
| AfC | but their approach to web server maintenance is brilliant. |
| AfC | Do you know what Google does if one web server dies? |
| AfC | NOTHING. |
| AfC | Do you know what Google does if 5 web servers in a rack are dead? |
| AfC | NOTHING. |
| AfC | The basically wait until an *entire* cabinet of machines have failed, then unplug their uplink and SAN link, and get a cart and wheel it back to the shop to be mass fixed / reprovisioned / whatever. |
| AfC | That means that they can maintain servers on an assembly line scale. |
| AfC | And that means less effort per failure - and more importantly - fixing things during the day shift, not at 3am. |
| AfC | Final quick trend: Akamai - a global caching company. They have > 10,000 servers in ISPs spread around the world. In this case, their admin problem was maintaining servers in datacenters they don't control and never see. So the machines are simple, they have *everything* in the kernel (web cache server, ET-phone-home control logic, etc); it boots off of flash. And they have multiple nodes per location; if one fails, no big deal. |
| AfC | THAT is the trend in Unix infrastructure management that is actually the heart of my talk: |
| AfC | "If it fails, no big deal" |
| AfC | Which is pretty impressive. |
| AfC | Of course it is possible to over simplify... |
| AfC | [[[ http://www.operationaldynamics.com/reference/talks/TrendsUnixInfrastructure/img4.html ]]] |
| AfC | Ok. Onto the meat: |
| AfC | [[[ http://www.operationaldynamics.com/reference/talks/TrendsUnixInfrastructure/img5.html ]]] |
| AfC | I've been going on about complexity, and its cost. |
| AfC | The significant trend in the broader Unix industry isn't a trend in the "young Japanese women like shiny new cell phones" sense, but rather is people trying to deal with challenges that, frankly, vendors don't give them help with. |
| AfC | What is really impressive is that faced with the task of trying to manage 10s or 100s of servers in a datacenter, university department, or business office, people quickly realized that "doing things by hand" wasn't good enough. |
| AfC | There are a number of problems: |
| AfC | * need to add systems (horizontal scaling) easily |
| AfC | * need to be able to deploy systems in the first place (roll out a 10,000 workstation trading floor, anyone?) |
| AfC | * need to be able to replace the entire infrastructure somewhere else in the event of disaster. |
| AfC | So people started figuring out ways to automate systems administration. |
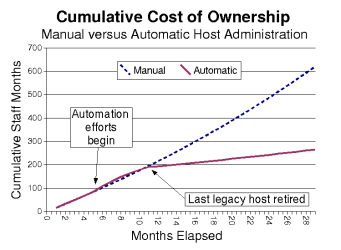
| AfC | One slide I forgot to put in was a reference to this chart, so I'll just link it directly: |
| AfC | [[[ http://www.infrastructures.org/papers/turing/images/t7a_automation_curve.png ]]] |
| AfC | This graphic acknowledges that implementing automation techniques does have an initial cost, but that you quickly break even in terms of staff time. |
| AfC | [[[ back to me, http://www.operationaldynamics.com/reference/talks/TrendsUnixInfrastructure/img5.html ]]] |
| AfC | the key learning in the Unix infrastructure world has been to view an organization's machines not as a group of individual nodes, but rather to deal with the system as a single entity - a virtual computer, if you will. |
| AfC | Everyone here has written little scripts to automate basic tasks, right? |
| AfC | How many of you have written automation tools which take care of deploying, configuring, and maintaining an entire group of machines *over time*? |
| AfC | Well, it turns out, it's a tricky problem. |
| AfC | In fact, it's incredibly difficult. |
| AfC | [[[ next slide http://www.operationaldynamics.com/reference/talks/TrendsUnixInfrastructure/img6.html ]]] |
| AfC | And that's another trend I want to mention. |
| AfC | This time it's a negative trend: |
| AfC | most people attempt to cook up their own ad-hoc solution to infrastructure and configuration management. |
| AfC | which is a terrible idea. |
| AfC | People have been at this for a while, people with huge datacenters, large research university campuses, investment bank trading floors, |
| AfC | and it turns out there are some unexpected traps. |
| AfC | Most of you will have heard of cfengine, by Mark Burgess |
| AfC | cfengine follows a strategy of "convergence" - it attempts to converge a systems config files to a desired end state. |
| AfC | the problem is that most of the time, it is not deterministic. |
| AfC | Alva Couch of Tufts University in the US, a computer science professor, showed this in a mathematical proof |
| AfC | which means that, unless you know what pitfalls to avoid, if you use cfengine you will, by definition, not know what state your system will end up in. |
| AfC | (which is no help) |
| AfC | The other major strategy is "congruence", which is when configuration files are generated, typically using some kind of macro substitution. The major problem that occurs here |
| AfC | is around specificity - let's say you have an Apache config for a normal web server, and an Apache config for a secure web serer, and you install them both on the same machine. What happens? |
| AfC | [isconf, psgconf follow these sorts of strategies] |
| AfC | which brings us to a generic problem in any configuration management system - how *do* you specify the configuration? |
| AfC | you need some language to express the configuration, and you want to be able to specify different configurations for different classes of machines (mail servers, web servers, dns machines, etc) |
| AfC | It's a tough problem. Many people have tried and stumbled :) |
| AfC | There is a long standing body of research on this topic; there has been an impressive amount of research published the LISA conferences over the last few years. The conference proceedings are available online at usenix.org (see my slide for a link) |
| AfC | See also two other primary resources: Mark Burgess (now a full professor of this stuff! Not bad for having started an open source project) maintains a lot of excellent material at the cfengine website, |
| AfC | and I would point you to the infrastructures.org website. |
| AfC | It's not definitive word by any stretch |
| AfC | (it's based on an 1998 paper at LISA) |
| AfC | but it represents the knowledge and best practice of some of the leaders in the field globally. |
| AfC | and its a good place to learn that there's more to infrastructure management than meets the eye. |
| AfC | Which is the second last trend I want to point out - that there IS a body of knowledge out there about this and several active global open source communities. |
| AfC | I am frequently disappointed when I hear someone in a Linux User Group say "oh, you can manage that with a for loop and ssh", or hear a vendor say "oh, all you need is Jumpstart and everything will be taken care of" |
| AfC | but we're the ones who run the systems.... and it's our opportunity to do better. |
| AfC | [[[ almost done! http://www.operationaldynamics.com/reference/talks/TrendsUnixInfrastructure/img7.html ]]] |
| AfC | The last trend I want to suggest is really just some fortune telling, but I see it coming and so will make a prediction: |
| AfC | grid computing will change the nature of systems administration. |
| AfC | [was just answer a few questions] |
| AfC | So here's something happening in the real world, today, at a major pharmaceutical company: |
| AfC | they have two 512 node cluster super computers (California and Geneva) and offices in California, Texas, and Geneva each with 1000 desktops or so. |
| AfC | they *globally load balance* |
| AfC | jobs |
| AfC | and, when it's night in California and Texas, all the desktops there get annexed as processing nodes for the cluster in Geneva |
| AfC | And it all Just Works (tm). |
| AfC | Now, that's a clustering example, but it sets the tone. Computers aren't individual machines. Collectively, they represent "computing power", and given that you've paid for you might as well leverage them. Cost factors are driving people to do so. |
| AfC | The thing is that when all the machines in an department/organization/company/university/whatever start being able to be part of a virutal super computer on demand, |
| AfC | then suddenly the problem is no longer "I need 10 web servers", but "I need computing power with the following characteristics to fulfill the following web serving task" |
| AfC | It's a matter of policy definition. |
| AfC | Even just in a data center or e-commerce platform, why should I say "this is web01, this web02, ... this is web26" |
| AfC | I really want to say: |
| AfC | "make sure there are sufficient web servers always online to handle normal traffic. If a surge is detected, bring up more web server instances on other machines. Oh, and bring up another database replica as well." |
| AfC | and, most of all, I want it to just figure that out by itself. |
| AfC | Do you see the fundamental shift in the nature of systems administration? It's still Unix; someone still has to configure Apache to work within whatever framework; someone still has |
| AfC | to get the tools in place, but the management of the infrastructure *as a whole* becomes radically different. |
| AfC | I think it's an amazing prospect. I think it will lead us to spending much less time mucking about with systems. |
| AfC | But, I am wary of one thing: the more abstracted a system becomes, the harder it will be to figure out what it is doing, and why. |
| AfC | Of course, humans are already like that. |
| AfC | I guess that's progress. |
| AfC | [[[ http://www.operationaldynamics.com/reference/talks/TrendsUnixInfrastructure/img8.html ]]] |
| AfC | Thanks for listening! |
| AfC | Questions to #qc, I'll answer here. |
| AfC | Espero que les haya gustado la presentación. |
| AfC | No duden en ponerse en contacto |
| AfC | conmigo si tienen alguna pregunta. |
| AfC | - |
| AfC | Os deseo unas buenas noches, y espero que tengan unas felices fiestas. |
| AfC | - |
| AfC | Por mi parte, pues, es una mañana preciosa aqui, y creo que me iré a la playa. |
| AfC | [Oh, re the grid stuff, the SmartFrog link I mentioned is going in these lines already] |
| fernand0 | Nice talk! |
| fernand0 | Thanks! |
| fernand0 | plas plas plas plas plas plas plas plas plas plas plas |
| fernand0 | plas plas plas plas plas plas plas plas plas plas plas |
| AfC | :) |
| fernand0 | plas plas plas plas plas plas plas plas plas plas plas |
| feistel | plas plas plas plas plas plas plas plas |
| feistel | plas plas plas plas plas plas plas plas |
| feistel | plas plas plas plas plas plas plas plas |
| feistel | plas plas plas plas plas plas plas plas |
| roel | nice, thanks |
| AfC | One thing from the question channel: |
| AfC | I would also observe that "recover my file that I accidentally deleted", and "oops, we lost the data center, now what?" are fundamentally different problems. Dealing with it is partly figuring out the separation of code/config/binaries (all replaceable) and data (irreplaceable) |
| fernand0 | plas plas plas plas plas plas plas plas plas plas plas |
| AfC | all this configuration management and infrastructure magic is about the code part. You still have to work out an intelligent strategy for protecting your data. That's still hard. I guess that's the last trend :) |
| AfC | Any other questions? |
| AfC | Comments? |
| AfC | Come on feistel - I know you can't resist :) |
| riel | interesting talk |
| fernand0 | Well |
| fernand0 | thanks for your talk |
| fernand0 | we'll put the logs in our web as soon as possible |
| riel | thank you AfC |
| AfC | riel: thanks for that pointer. |
| trulux | cla clap clap |
The Organizing Comittee

{kind=link}